CSV Reader
The CSV Read transform takes Character Separated Value (CSV) files as the data-source.
This transform can parse a wide variety of CSV data including Hierarchical Data, tab delimited and Unicode files.
Example
A typical CSV file, shown below, has a fixed number of fields which are separated by commas. These can contain an empty value, but would be held between the two Separating Characters.
Reader > File Layout
The file layout tab is where the file and hierarchical dataset options are specified.
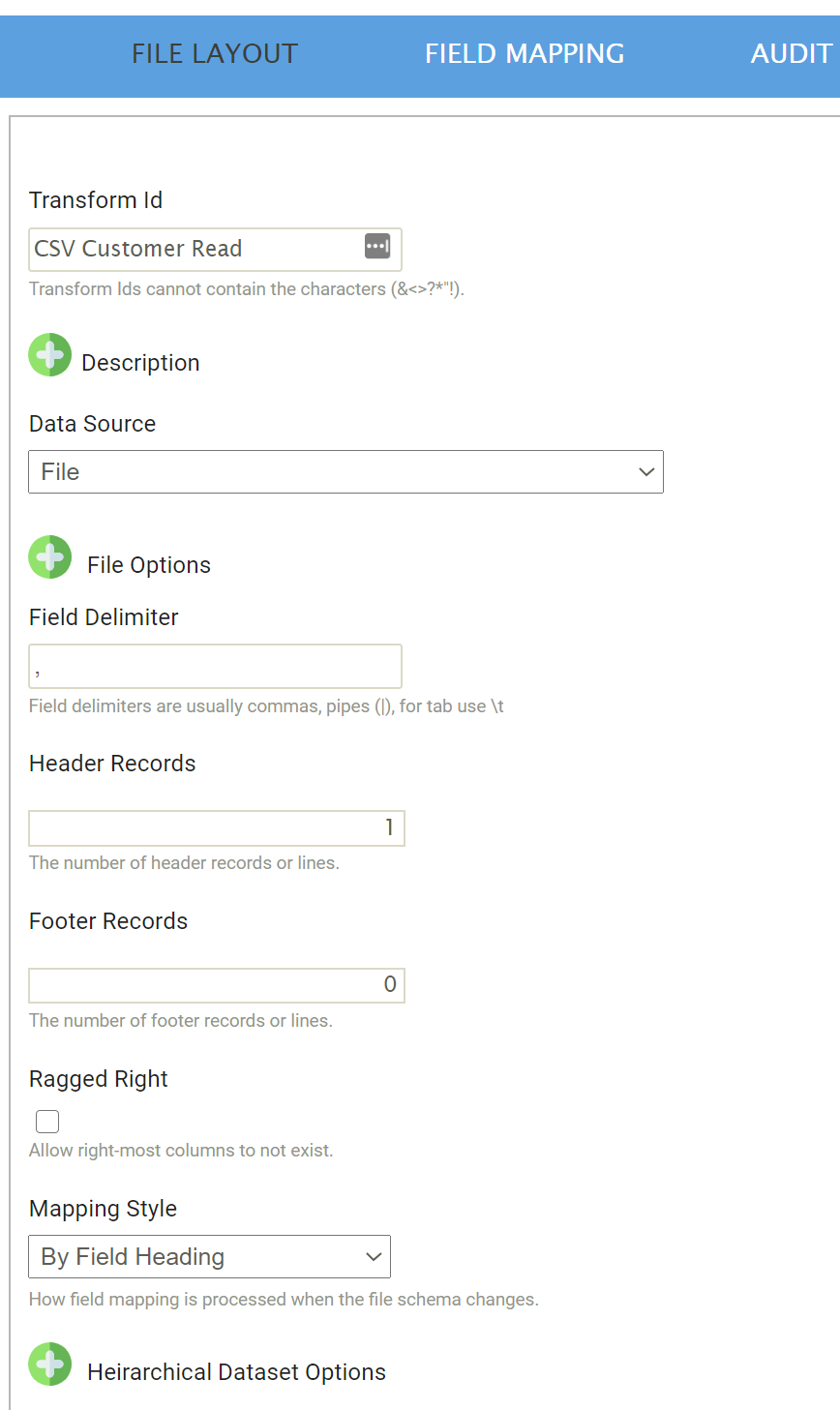
Transform Id
The unique user-defined name for the transform.
Data Source
The controller type is defined here. This is the source from where the CSV data will be read, which can be Email, File or Http.
See Input/Output Controllers (IO Controller) for more information.
Field Delimiter
The character(s) used to separate each of the fields.
The delimiter may use 1 or more characters.
To specify tab delimited files, enter \t.
Header Records
The fixed number of rows at the start of the file which are filled with content that is not data.
Since the CSV is a text file, the most likely use of header rows will be field headers.
Footer Records
The fixed number of rows at the end of the file also filled with content other than data. All content within the footer rows will be ignored when reading the data.
Ragged Right
- Selected
- When selected the Reader allows files where the right most fields may be missing (as opposed to empty) from the file. Where a field(s) is missing the reader will simply read an empty (or null) value.
Ragged Right type files are often encountered when CSV files may have numerous empty values on the rightmost values, the file is opened in Excel, and then saved. Excel will drop the empty right values from the file.
- When selected the Reader allows files where the right most fields may be missing (as opposed to empty) from the file. Where a field(s) is missing the reader will simply read an empty (or null) value.
- Deselected
- When deselected the CSV Reader will check the line being read to ensure the number of fields matches that of the Reader definition. An error will occur if a line does not have a matching number of fields.
Mapping Style
- By Position
- Fields will be mapped according to their position.
- By Field Heading
- Fields will be mapped according to their headings. Available only when headings are detected within the file.
Hierarchical Data
A hierarchical dataset can be generated from a CSV file, if the records within the file are identified as having different transaction types (i.e. headers and details).
For the hierarchy to be created:
- There must be a field within the data that identifies the type of record (i.e. header/details/sub-detail etc.)
- The field identifying the transaction type must be located in the same field position for all records.
Example
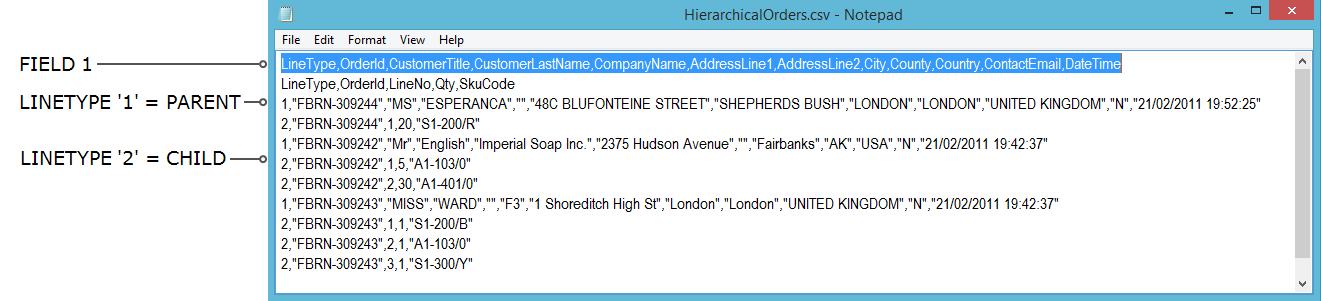
The screenshot below illustrates a file with a hierarchical structure.
The first field identifies the transaction type for all records. In this example, “1” denotes a sales order header, and “2” denotes an order detail/line item.
Hierarchical Dataset Options
To configure a hierarchical dataset, expand Hierarchical Dataset Options.

Hierarchical Dataset
Keyed Fields
The key field is used to construct a hierarchical dataset. For this reason, keys are assigned either on import, if the dataset is already hierarchised, or in the hierarchy transform.
By giving a record a numerical value, the parent-child relationships are defined. Child records are inserted into the dataset when its keys match those of its parent’s.
When setting the keys, each child transaction must have at least one more key defined than its parent.
These are defined in the field mapping tab of the Hierarchy transform.
Ordered Data
On import, the structure and relationship IMan identifies between fields relies on the order of the data within the file.

Record Type Field Id
This dropdown provides the ability to select the field position identifying the transaction type. In the screenshot example above this is the first field which in this case is named 'LineType'.
This drop down is enabled only when the hierarchical dataset checkbox is selected.
Hierarchy Detection Results
Pressing the Refresh button will cause IMan to parse the CSV file(s) per the IO Controller settings to detect the different transaction types. In the example above, two transaction types are detected: 1 and 2.
Reader > Field Mapping
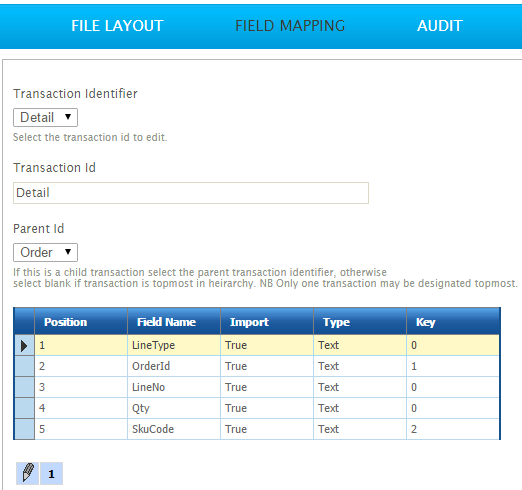
Transaction Identifier
If a Hierarchical Data dataset, each Transaction detected in the CSV file will be listed in this drop-down; if it is a flat dataset, only one Id will appear here. Selecting an Id from this list will open it for editing.
Changing the selected Id on this drop-down will save the currently active Id and open the newly selected transaction into the field mapping grid.
Transaction Id
The Transaction Id can be edited here, if the user chooses.
To see changes made to this Id, it is necessary to close off the setup window, and load it again from the Transform Setup screen.
Parent Id (Hierarchical Datasets Only)
The Parent Id specifies which immediate parent the selected transaction id is associated.
Select from the drop down the desired parent to build the logical hierarchy.
Position
The position of the field in the file. The position of a field is fixed and cannot be edited.
Field Name
The unique name of the field.
Import
When set to True, the field is included in the resultant dataset.
When set to False, the field will be dropped from the dataset.
Type
The data Field Types of the field.
Key (Hierarchical Datasets Only)
The key applies to Keyed Hierarchy datasets only because it is used to insert fields into the correct place within the dataset depending on their relationship to other records.
The Key fields of the record being inserted must match the parent records keys.
Each child transaction type must have at least one more key defined than its parent transaction type. This is due to the nature of the structure being built.
Populating the Field Mapping Grid
If valid values have been entered into the File Path, Name and Delimiter fields and there are no errors after pressing the refresh button, the fields from the CSV file will populate the grid on the Field Mapping tab. When this does occur, the file has been successfully read to extract the transaction types and fields.
File Parsing Process
In conjunction with options specified on the Options tab, the read transform engine uses the following inbuilt properties to read a CSV file:
Line Delimiter
The transform engine auto detects the line delimiter.
The delimiter can be any of the following:
|
Name |
Symbol |
Unicode Value |
|---|---|---|
|
Windows |
CRLF |
U+000D & U+000A |
|
Unix |
LF |
U+000D |
|
Mac (Up to Os 9) |
CR |
U+000A |
|
Form Feed |
FF |
U+000C |
|
Next Line |
NEL |
U+0085 |
|
Paragraph Separator |
PS |
U+2029 |
|
Line Separator |
LS |
U+2028 |
Text Qualifier
The read transform automatically detects and removes text qualifiers (“ or ‘) around fields.